
Improve Subgraph Indexing Performance Easily: Reduce eth_calls
Welcome to the inaugural edition of the . The purpose of this series is to share insights and recommendations based on patterns that have emerged since . An incredible amount of new features were shipped since its inception, leading to tens of thousands of subgraphs being built across the web3 ecosystem. (decentralized open source APIs) enable developers to create fast front ends for their dapps and have become an integral layer of . However, with increased usage comes increased demand in discovering efficiencies, and both new and experienced subgraph developers often seek to discover and implement best practices.
This new development series will equip you with tips and tricks to level up your subgraph development skills, helping you create more efficient and speedy dapps! With this debut edition, let’s begin with an oft-overlooked best practice that is very simple to implement and has massive benefits.
Part 1: Reduce eth_calls: A simple indexing performance improvement
It can be frustrating when your subgraph is indexing slower than you’d anticipate. Sometimes developers inadvertently end up testing the limits of indexing performance. Developers in The Graph ecosystem are working on technologies that will massively improve the performance and capabilities of decentralized data, such as and . Nevertheless, subgraph developers may often see quite significant improvements in terms of indexing performance and query speed by simply optimizing their subgraph. The most often mentioned improvement is to reduce or completely avoid state through . Let’s dive into one solution.
Why reduce eth_calls?
A common dapp setup resembles this illustration:
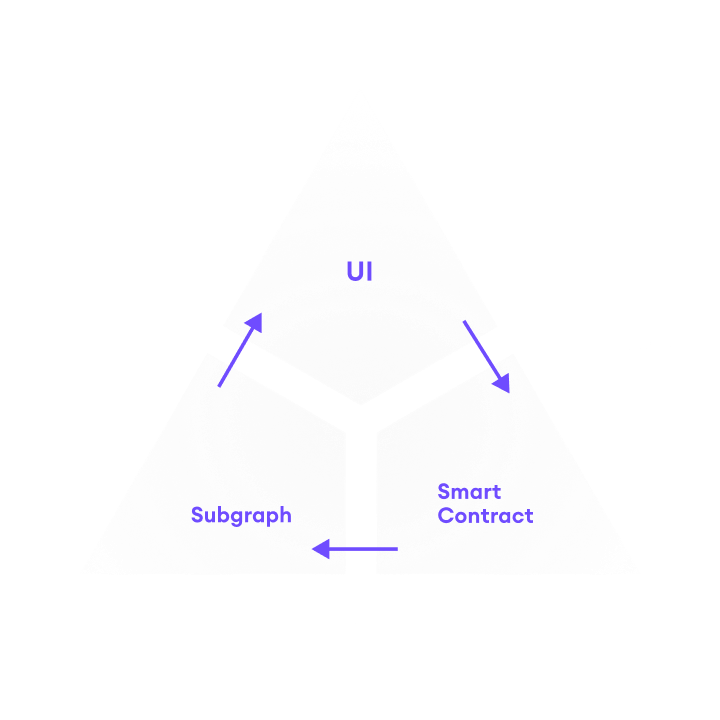
In this model, our dapp’s UI displays all the necessary data directly from the subgraph, as seen on the left side, so there is no need to fetch any data directly from the blockchain node through JSON RPC. If users interact with a dapp’s smart contract, they send a transaction which will change the smart contract’s state, as seen on the right side of the illustration above. Examples include mints, transfers, swaps, etc. When the smart contract state changes, it emits events that the subgraph is subscribed to. Listening for and indexing the data emitted in events is a very performant pattern.
Unfortunately, many smart contracts do not emit all necessary data in their events directly. To determine the new smart contract state after a completed transaction, it is often necessary to send an back to the smart contract to retrieve that data. However, JSON RPC calls are generally slow. Each call usually takes 100ms up to several seconds to resolve. That’s why developers are discouraged from using them at all in their UIs for displaying information. These eth_calls are also slow if they run as part of the mappings inside the Graph Node. Thankfully, there are patterns to reduce them:
Background info: In order to handle reorgs properly and index historical data, Graph Node leverages by adding the block-hash as a parameter to the eth_call. This guarantees that the result of the call comes from the final state of the block in which the event was emitted. There are edge cases though where the state of a contract changes intra-block between the emitted event and the finalisation of the block. Another good reason to prefer events. Specifying the block-hash also makes the eth_call more difficult for the Ethereum node to resolve.
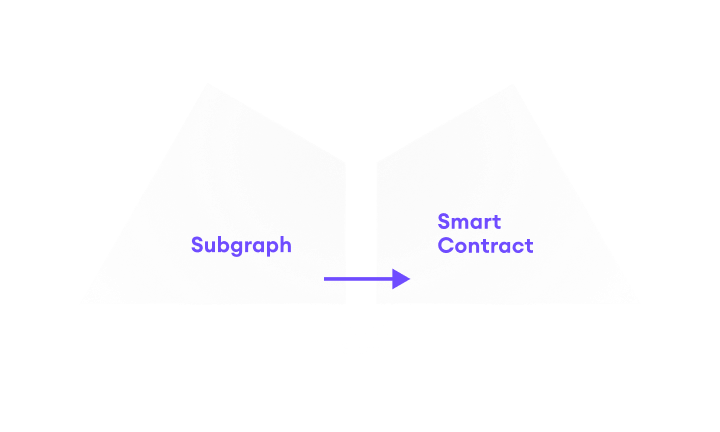
If we can still change the contract because it is still under development or upgradeable, we should try to emit all necessary data up front in the event. However, sometimes we can not change the contract anymore, so we need to fall back to eth_calls. In that case, it is advised we try to minimize the amount of eth_calls.
As described above, eth_calls always return the state of the smart contract at the end of the block the call is made. If the state of the contract did not change as the chain progresses, making these calls is just an expensive way to look up data that we already retrieved. So one common pattern to avoid this is to store the result of an eth_call in the subgraph and only send that call if the data is not known yet.
Example Schema
Let’s look at an example of a simple NFT subgraph. In this exercise, we want to keep track of the total amount of mints for this hypothetical NFT project, and the metadata for each token. Our example subgraph would have the following schema:
type Token @entity {id: Bytes!owner: Bytesuri: Stringcontract: Contract}type Contract @entity {id: Bytes!name: Stringsymbol: StringtotalSupply: BigInttokens: [Token!]! @derivedFrom(field: "contract")}
An entity in the schema can be read as a database table definition: This schema describes a token table that contains all tokens with its holders, and a contract table that has only one entry (singleton) to hold information about the contract.
Naive Implementation
A naive mapping would look like this:
import { Bytes } from '@graphprotocol/graph-ts';import { ERC721, Transfer as TransferEvent } from '../generated/ERC721/ERC721';import { Token, Contract } from '../generated/schema';export function handleTransfer(event: TransferEvent): void {let instance = ERC721.bind(event.address);let contract = new Contract(event.address);contract.name = instance.name(); // eth_callcontract.symbol = instance.symbol(); // eth_callcontract.totalSupply = instance.totalSupply(); // eth_calllet token = new Token(Bytes.fromI32(event.params.tokenId.toI32()));token.owner = instance.ownerOf(event.params.tokenId); // eth_calltoken.uri = instance.tokenURI(event.params.tokenId); // eth_calltoken.contract = contract.id;contract.save();token.save();}
Note: For the sake of simplicity, we did not handle the possibility of the calls to revert. In production code it is highly recommended to do so according to the .
Let’s review that mapping. As seen on line 6, the ERC-721 contract is bound to the address of the contract which emitted the Transfer-Event. Usually, getting a bound contract instance is an indication that eth_calls will follow. To find the eth_calls in a subgraph one can usually just search the code-base for “.bind(“.
On line 8 a new entity (read: row in a table) is created. This is where a subgraph developer should begin to question: Why are we creating a new entity? There could already be an entity in the database. On the following lines, the actual eth_calls are triggered to get the name, symbol and total supply of the contract. Remember that these calls are triggered for every Transfer-event. An NFT contract with many Transfers would trigger thousands of eth_calls. Most of them are actually unnecessary since the name and the symbol of an NFT contract usually don’t change. Only totalSupply might change as long as this NFT can be minted.
Forward to line 13 with the block about the token itself. Similar behavior is witnessed here: the owner changes on every transfer, so an eth_call here might be reasonable to retrieve the new owner. The tokenURI, though, should not change.
Optimized Implementation of eth_calls
How can we optimize this mapping to have less eth_calls? There are two main strategies here:
- Cache the result of the eth_calls
- Use data from the event itself and calculate information in the subgraph
This is how an optimized mapping would look like:
import { Address, BigInt, Bytes } from '@graphprotocol/graph-ts';import { ERC721, Transfer as TransferEvent } from '../generated/ERC721/ERC721';import { Token, Contract } from '../generated/schema';const ZERO_ADDRESS = Address.fromString('0x0000000000000000000000000000000000000000',);function getOrCreateContract(address: Address): Contract {let contract = Contract.load(address);if (!contract) {let instance = ERC721.bind(address);contract = new Contract(address);contract.name = instance.name();contract.symbol = instance.symbol();contract.totalSupply = BigInt.fromI32(0);contract.save();}return contract;}function getOrCreateToken(tokenId: BigInt, address: Address): Token {let id = Bytes.fromI32(tokenId.toI32());let token = Token.load(id);if (!token) {let instance = ERC721.bind(address);token = new Token(id);token.uri = instance.tokenURI(tokenId);token.contract = address;token.save();}return token;}export function handleTransfer(event: TransferEvent): void {let contract = getOrCreateContract(event.address);let token = getOrCreateToken(event.params.tokenId, event.address);token.owner = event.params.to;token.save();// A new token was minted if it comes from addressif (event.params.from == ZERO_ADDRESS) {contract.totalSupply = contract.totalSupply.plus(BigInt.fromI32(1));contract.save();}}
First, we introduce helper functions for both the contract and the token. The helper functions first try to load an entity from the database. Only if they do not exist yet, they send eth_calls to load the necessary data. They also set defaults if needed as on line 17, where the total supply of a new contract is set to zero.
In the actual handler function, these helper functions are leveraged. So if a token and the contract already exist, they do not send a single eth_call at all. On line 43 we use the data that comes with the emitted event. We know who is the new owner of that token by looking at the `to` parameter of the event.
On line 47 and 48 we can calculate the totalSupply inside the mappings without any eth_calls: If the token is newly minted, we will observe a `from` parameter with the zero address. If this is the case, we can simply increase the totalSupply by one.
Continued optimization
With the introduction of helper functions, we were able to minimize the amount of eth_calls in this example. The result is a tremendous increase in indexing performance of the subgraph. Similar patterns can be applied to other challenges:
- Only do eth_calls once
- Store the result of the eth_calls in the database
- Try to calculate the state of the smart contract inside the subgraph
A more complex example worth mentioning here is the optimization of a Uniswap clone by and , .
Thank you for reading the first edition of the Best Practices in Subgraph Development series. Make sure to follow or join the conversation on to read future articles on how to sharpen and improve your subgraph development game!
This guide was written in collaboration with , , and from Edge & Node, along with and of The Graph Foundation.
About The Graph
The Graph is a suite of blockchain data infrastructure products that extract, process, and deliver scalable blockchain data solutions across 60+ networks. The Graph enables application developers, data analysts, AI agents, and enterprise teams that need structured, real-time access to blockchain data. Products include Subgraphs, Firehose, Substreams, and Amp. As of early 2026, The Graph has served over 1.27 trillion queries to more than 75,000 projects, powered by a network of independent Indexers around the world.
Follow The Graph on , , , and . Join the community on The Graph’s , join technical discussions on The Graph’s .
