
Using AI To Enhance The Graph Network
This blog post is brought to you by Sam Green and Tomasz Kornuta of , a core developer of The Graph.
In December 2021, Semiotic . While our charter is to focus on using research to bring new artificial intelligence (AI) and cryptography capabilities to The Graph, we also have an applied and impact-oriented mindset when it comes to contributing to the protocol. We have done so by operating an Indexer on The Graph Network, which requires specialized DevOps skills, and we have operated a competitive Indexer, , since early 2021. Additionally, we have used our AI expertise to release two automation software tools to The Graph ecosystem: AutoAgora and the Allocation Optimizer.
This post provides an overview of our past and current AI efforts, and it outlines future ideas for how The Graph’s unique data indexing capabilities can be leveraged for AI applications.
Why The Graph is Ideally Positioned to Leverage AI
The Graph is a decentralized protocol for indexing blockchain data and making it available for querying for use in downstream applications, like dapp frontends, plots, dashboards, or data analytics. There are many use cases for AI in The Graph. To date, the primary AI use case in The Graph has been the deployment of tools for automated decision-making. An emerging AI use case is to lower the barrier to entry to access the rich web3 data indexed by The Graph. We’ll primarily focus on the former use case – using AI for automation within The Graph.
The Graph, and decentralized protocols in general, use incentive mechanisms to encourage protocol participants to behave optimally and honestly. An incentive mechanism is a reward for desired behavior – it is a concept from behavioral economics. For example, in The Graph, consumers incentivize Indexers to serve queries by paying them GRT. Similar mechanisms exist for Indexers, Curators, Delegators, and Fishermen, they all have that guide their behavior.
An implication of building a decentralized protocol is that decision-making is moved away from a centralized entity (e.g. a corporation) and towards participants in the protocol. In the context of The Graph, decentralization results in participants needing to make many complex decisions. Semiotic Labs uses AI and related techniques to deploy tools that simplify the decision-making process for protocol participants. We have contributed to the development of two AI-related tools: AutoAgora and the Allocation Optimizer. Both of these tools help Indexers increase their protocol performance and revenue.
AutoAgora
At the very core, the purpose of The Graph is to serve queries to its users. In a simplified scenario, the protocol involves multiple Indexers (data sellers), consumers (data buyers), and gateways. When a customer sends a query to one of several gateways, the gateway distributes the query between Indexers based on various factors such as Indexer's price-bids, their quality of service (QoS), latency, and so on. Indexers earn money by serving queries, while free to control the prices of the queries they serve. This process is depicted below:
Indexers express their price-bids for various GraphQL queries in the form of a model defined in a domain-specific language called Agora. An Agora price model maps queries to their prices in GRT, i.e. provide a concrete price for how much a given Indexer would execute the query. However, creating and updating Agora models for each subgraph can be a tedious and time-consuming task, so many Indexers use a static, flat pricing model instead.
To help Indexers with pricing and ensure they are following the market price for queries, Semiotic Labs created an open-source tool called . AutoAgora automates the process of creating and updating Agora price models, making it easier for Indexers to offer dynamic pricing that reflects the actual cost of serving a particular query shape. In short, AutoAgora is a useful tool for Indexers who want to offer more competitive and flexible pricing for their query services on The Graph Network.
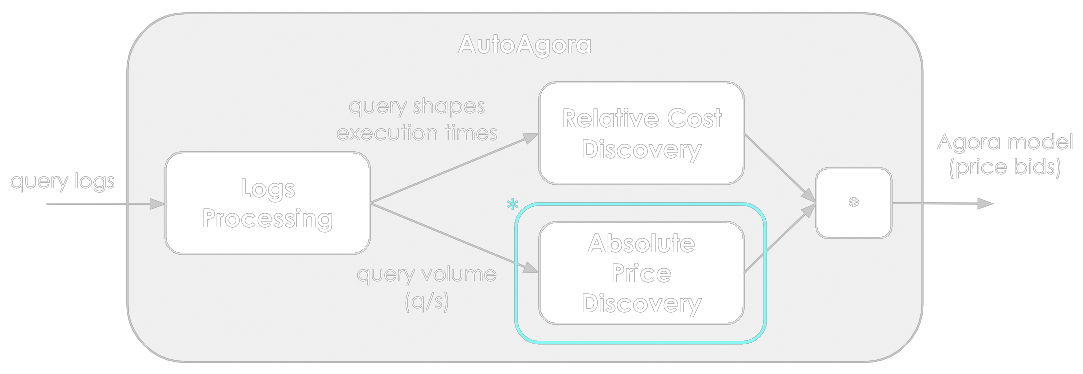
As presented above, AutoAgora consists of several modules that work together to automate the process of creating and updating Agora price models. These modules include:
- Logs Processing: parsing the logs in order to extract the incoming queries, their shapes, and execution times;
- Relative Cost Discovery: grouping similar query shapes and calculating their resource usage statistics (e.g. mean execution times);
- Absolute Price Discovery: trying to maximize the revenue by adjusting the prices depending on the query volume served in the past.
We use AI in the Absolute Price Discovery module, indicated with the red frame in the image above. This module implements a gaussian bandit, i.e. a type of trainable, stochastic agent used in reinforcement learning. In the context of pricing queries, the policy for the agent is represented as a Gaussian distribution over the possible query prices, and the action taken by the agent is sampled from this policy distribution. Once sampled, the price is used to update the Agora model, subsequently sent to one of several gateways. Abstracting from all the technical complexity (and simplifying a lot), the logic that the bandit uses to update its policy can be described as follows: if an Indexer running AutoAgora serves a huge volume, then the price should be increased, and if there are no queries served, then clearly the price is too high.
For more general information on AutoAgora please refer to our describing details of the infrastructure or our from Graph Hack in June 2022. More detailed information on the Reinforcement Learning and Gaussian bandits can be found in our and a we gave at DevCon VI in October 2022.
The Allocation Optimizer
There are currently more than 750 subgraphs deployed in The Graph Network. Before a consumer can make subgraph queries, an Indexer must “sync” the blockchain data related to the subgraph and then allocate GRT to the subgraph. Syncing a subgraph and then serving queries is a very resource-intensive task, so Indexers usually do not sync all subgraphs. In practice, The Graph Network looks something like the following illustration, with Indexers allocated to only some of the many possible subgraphs:
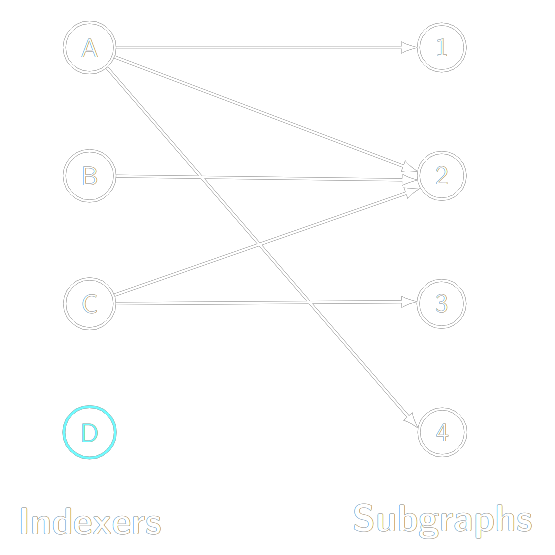
How do Indexers know to which subgraphs they should allocate? That’s the role of Curators. Curators signal (temporarily deposit) GRT on subgraphs. Curators themselves are rewarded if query fees on a particular subgraph increase, so rational Curators will try to signal on subgraphs with high query fees. Correspondingly, the protocol economics nudge Indexers towards high query fee subgraphs so that they serve those queries. By following the signal, Indexers will end up on subgraphs with query fees. However, the allocation problem isn’t that easy. It wouldn’t work if all Indexers indexed only the subgraph with the highest signal. If that were the case, no other subgraphs would be served. As a result, the indexing reward rewards Indexers for being on subgraphs with high signal, but also penalizes them for being on subgraphs on which there is already a lot of stake allocated by other Indexers. To figure out which subgraphs to index, Indexers must follow the indexing reward, not the signal.
For many Indexers, following the indexing reward is non-trivial. In fact, the full problem turns out to be optimizing a submodular function, which is still not a solved problem in the academic literature. The is an open-source tool for Indexers that at least gets part of the way there. The tool takes as input the current state of curation, the existing allocations of other Indexers, the amount of GRT available to a particular Indexer, and gas costs. The tool then solves an optimization problem on behalf of the Indexer. The output of the Allocation Optimizer is a recommendation for the Indexer. The recommendation includes which subgraphs should be allocated to and how much to allocate.
Allocation optimization is a difficult mathematical problem, but solving mathematical problems does not, by itself, improve the protocol. By providing Indexers with a tool that can calculate their optimal allocation, we can increase their indexing rewards revenue and free some of their time so they can focus on providing high-quality service for subgraph queries.
The Future of AI and The Graph
In this post thus far, we have focused on the AI-related tools that are deployed presently for use in The Graph Network. But how else can The Graph leverage AI? And, from another perspective, how can AI builders leverage The Graph?
The release of ChatGPT was the iPhone moment for AI – it is a tool that democratizes access to AI. ChatGPT is a brand name for what is more generally known as a Large Language Model (LLM). LLMs are powerful for summarizing and synthesizing text data. They can also be used for processing numerical data, but getting LLMs to do math correctly is still an emerging area of research. We have started a pilot project to use LLMs to access and summarize The Graph’s vast amount of information. Specifically, we will enable anyone with an interest in web3 data to access it intuitively with natural language. Stay tuned for more details.
How can AI builders leverage The Graph? One way is to use The Graph’s data for training new AI models. You may have heard that training neural networks requires a lot of data, and that is exactly what we have in The Graph. Additionally, if you have a computer science background, you may have heard “garbage in, garbage out”, which refers to the fact that bad inputs should be expected to provide bad outputs. ChatGPT, GPT-4 and other LLMs have the “garbage in, garbage out” problem, because they are trained on much of the public (and therefore false or contradicting) data of the internet. This is one of the reasons ChatGPT is often wrong. One of the superpowers of The Graph’s data is that it is verifiable, which means that it is accurate. So we have a lot of accurate data that could be useful for training more trustworthy AI systems.
Empowering The Graph Network with AI
While the protocol is more widely recognized for data indexing than AI, The Graph does have many attributes required for effectively leveraging AI across its stack. For Indexers, Semiotic Labs has created open-source AI tools to automate complex decision-making that can both improve the efficiency of the protocol and Indexers’ revenue. For users of The Graph, we have started a pilot project that will give access to The Graph’s rich data using natural language queries. And, in the future, The Graph could become a source of trusted, verifiable data for training new AI models. If you want to hear more on those topics please listen to the of the where we discuss those (and other AI-related topics!) in a greater depth.
About the Semiotic Labs AI Team
Ahmet S. Ozcan
is Semiotic’s co-founder and CEO. Prior to his current role, Ahmet served as the manager of the Machine Intelligence group and led brain-inspired AI algorithm research and hardware acceleration, including the first application development on the . Ahmet holds a Ph.D. in physics from Boston University and is an IBM Master Inventor with over 100 filed patents to his name. His extensive research contributions include over in leading scientific journals, spanning diverse disciplines such as Computer Science, Cognitive Psychology, Neuroscience, Physics, and Microelectronics.
Sam Green
is a co-founder and Head of Research at Semiotic. In 2009, after finishing a Master’s degree in Applied Math, he worked for an embedded electronics consulting company where he developed low-level microcontroller code for real-time applications. In 2010, he joined Sandia National Laboratories where he specialized in using statistics and machine learning to analyze cryptographic hardware for weakness. In 2015, Sam left Sandia to pursue a Ph.D. at the University of California, Santa Barbara. combined Deep Learning and Reinforcement Learning and focused on building AI agents that can efficiently perform (e.g., low-power or high-speed) decision-making under uncertainty. He worked for Sandia again while finishing his degree and pursued research .
Alexis Asseman
Alexis is a co-founder and Lead Developer at Semiotic. After completing his Master’s degree in Micro and Nano Technologies, he joined the Machine Intelligence department at IBM Research. While at IBM, Alexis was the lead developer on the IBM Neural Computer which was built using over 400 FPGAs (high-performance reconfigurable hardware). He used the Neural Computer to perform large-scale . Alexis has also performed research on and . He also helped build , an open-source deep-learning library.
Anirudh Patel
is a Senior Research Scientist at Semiotic. Anirudh has a Master’s degree in Electrical Engineering focusing on Signal Processing from Stanford. In graduate school, whilst working on medical image processing, he was motivated by the successes of deep learning in chest x-ray pneumonia classification. He pivoted his focus to computer vision as a result. After completing his Master’s degree in 2018, Anirudh went to Sandia National Laboratories where he contributed to research and development projects as a deep learning “Subject Matter Expert”. As a result, he worked on projects across many different areas of deep learning such as , , Object Detection, and . At Sandia, he often served as a screening test for the feasibility of research initiatives and organized workshops and training to increase interest in Deep Learning techniques. By the time he joined Semiotic, he had specialized in .
Tomasz Kornuta
Tomasz joined in 2022, as VP of Engineering and Head of AI. Tomasz holds a Ph.D. in robotics and control and in the past worked on various problems combining with , applied to , and . In 2015, he joined IBM Research, where he conducted research on , and multimodal machine learning for and . In 2019, Tomasz joined the NVIDIA AI Applications team and got more involved in pure natural language processing research, working on and semantic search, leveraging the latest advancements in self-supervised learning and Large Language Models (LLMs). Tomasz is the author of and inventor of 4 US patents, with topics spanning from robotics and control, to computer vision, natural language processing, and machine learning. He also organized a dozen of conference devoted to those topics. Tomasz also served as a for various journals and conferences, as well as edited . Finally, he participated in a , including a DARPA funded grant and two 7th Framework Programme grants from the EU.
About The Graph
The Graph is a suite of blockchain data infrastructure products that extract, process, and deliver scalable blockchain data solutions across 60+ networks. The Graph enables application developers, data analysts, AI agents, and enterprise teams that need structured, real-time access to blockchain data. Products include Subgraphs, Firehose, Substreams, and Amp. As of early 2026, The Graph has served over 1.27 trillion queries to more than 75,000 projects, powered by a network of independent Indexers around the world.
Follow The Graph on , , , and . Join the community on The Graph’s , join technical discussions on The Graph’s .

